Learning Getting-Up Policies for Real-World Humanoid Robots
- Xialin He *1
- Runpei Dong *1
- Zixuan Chen 2
- Saurabh Gupta 1
- 1University of Illinois Urbana-Champaign
- 2Simon Fraser University
- *Equal contribution
-
RSS 2025
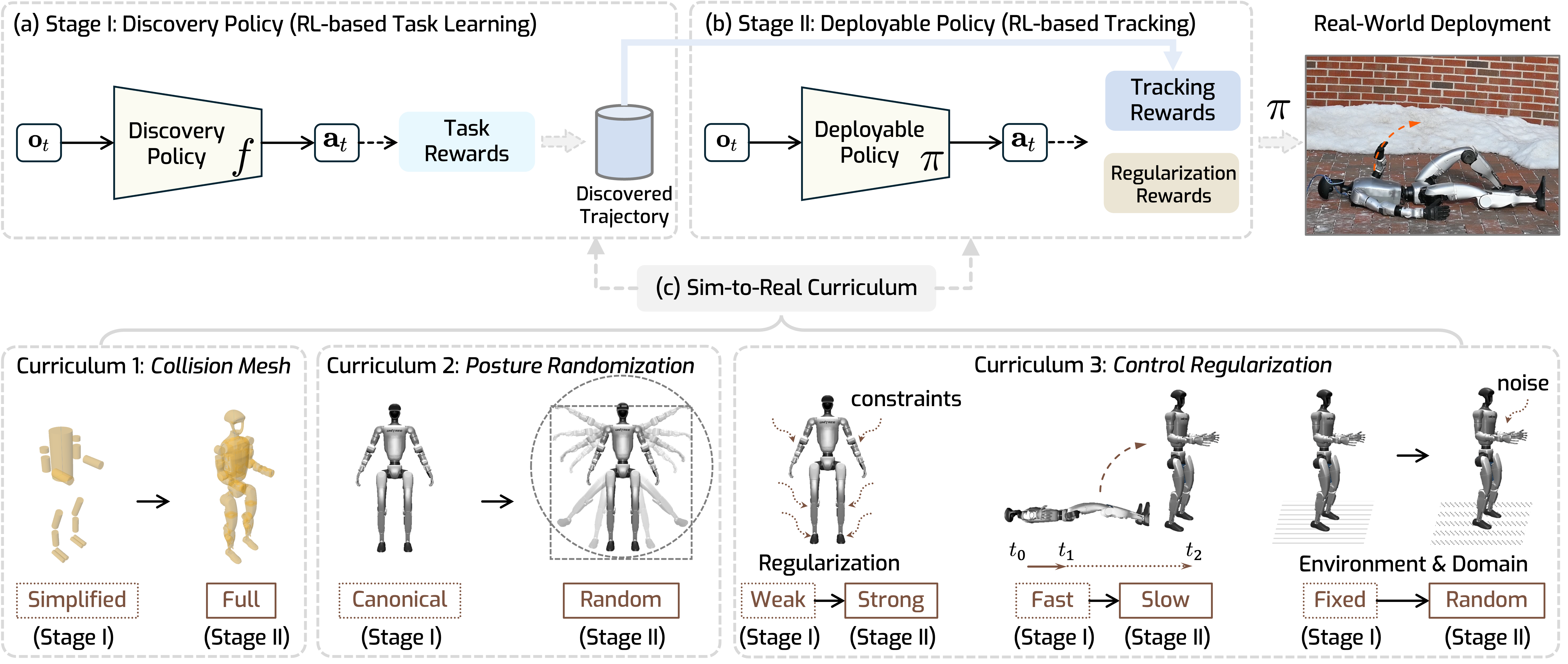
This project presents an RL-based approach that first achieves real-world humanoids getting up from arbitrary lying postures and terrains.